I've had my team working on adding value to JD Edwards using ChatGPT, as blogged about previously. My notes last time showed some basic interactions with ChatGPT - allowing it to create attachments to JD Edwards transactions based upon dynamic queries that are being sent to the generative AI platform. This was good, but we wanted it to be better.
We've been working out how we can use our own data to help Generative AI benefit us. The smarter people that I work with have been starting to dabble in LangChain.
Chain is critical in the definition of this framework - Chains allow us to combine multiple components together to create a single, coherent application. For example, we can create a chain that takes user input, formats it with a PromptTemplate, and then passes the formatted response to an LLM. We can build more complex chains by combining multiple chains together, or by combining chains with other components.
LangChain is a framework for developing applications powered by language models. It enables applications that are:
Data-aware: connect a language model to other sources of data
Agentic: allow a language model to interact with its environment
The main value props of LangChain are:
Components: abstractions for working with language models, along with a collection of implementations for each abstraction. Components are modular and easy-to-use, whether you are using the rest of the LangChain framework or not
Off-the-shelf chains: a structured assembly of components for accomplishing specific higher-level tasks
Off-the-shelf chains make it easy to get started. For more complex applications and nuanced use-cases, components make it easy to customize existing chains or build new ones.
It makes sense to use collaboration when trying to get advantage from AI and more specifically generative AI.
We did look at using either fine tuning vs embedding with native chatGPT, but this seemed to not provide us exactly what we needed.
What we decided to do is to use LangChain to assist us understand more about JDE data. JDE data comes in many forms, and lucky for us - LangChain is able to use numerous consistent document types as input. Such as SQL, CSV and PDF.
This means that we can produce a chain like the below - by creating a vectorStore of user specific JDE data which will allow an end user to securely query the data that they have access to, using or chaining the technologies or models of their choice.
So I imagine a time that I can basically use row & column security from JDE and being to load a users Vectorstore with all data that they have access to. Then allow this data to augment is answer complex and adhoc queries that a user might have. Remember that these queries could be structured via APIs or ad hoc via humans.

What we have done with WSJ and some pretty cool programming and UDOs:
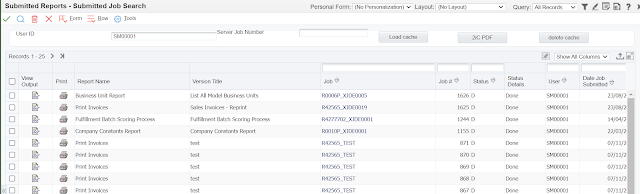
You can see from the above that we are fairly basically programming some User Defined Objects to call orchestrations from WSJ. What these do essentially mimic what could be done automatically or programmatically. These buttons give the end user the ability to create their own VectorStore using LangChain APIs which then allows an end user to perform adhoc generative AI queries against the files.
For example, I can select one of the PDF files and choose "load cache" button. This uploads the PDF file to my personal location for additional queries. This does this action securely. My file is not training the ChatGPT model.
I can then query the contents (fairly basically once again - hey be nice... I'm doing all the JDE work here).

I have asked a simple question, but I could have made it quite complex - you can ask it anything. this has been basically programmed to prompt for input before calling the orchestration to LangChain.

Okay, so wait... Back the truck up... I've been able to engage LangChain and ChatGPT using orchestration studio to ask ad-hoc questions about either my PDF or CSV output from JDE? This is amazing.
I can therefore schedule these queries, or I can keep the [basic] interface adhoc.
Let's try a little more now.

This is getting cool. I have a 2017 page report loaded and can ask any queries about this file. For example I asked about the unique customers in the invoice print run.
I then asked is there consistent pricing amongst all of the invoices?

Oh wait, the final result is not great - given the above. But good to know

This is the best result so far... This shows why you need to start asking questions and knowing about AI...
I asked for a 200 word summary of the report and asked for any anomalies that have been detected:
The report contains multiple invoices from the Worldwide Company to various customers. Each invoice includes details such as the invoice date, customer information, order number, item description, quantity, price, extended price, and tax. The items sold are primarily College Rule Paper.
The invoices are addressed to different customers, including Capital System and ABC Big Box Store, and are shipped to various locations. The invoice dates range from 2016 to 2023, and the prices for the College Rule Paper vary slightly across the invoices.
One anomaly in the data is the reprinting of invoices, which could indicate a correction or duplication. Another anomaly is the presence of unprocessed sales order lines mentioned at the end of the report. This could suggest incomplete transactions or issues in the order processing system.
The report also includes freight charges under the 'Invoice/Type' section, which are not consistently present in all invoices. This inconsistency could be due to different shipping methods or terms agreed with different customers.
Overall, the report provides a comprehensive view of the sales transactions of the Worldwide Company, but the anomalies suggest potential issues that may need further investigation.
You know you want this for your JDE, all you need to do is ask!