At Fusion5 we are doing lots of upgrades all of the time, so we need to understand our clients technical debt. We strive to make every upgrade more cost efficient and easier. This is easier said than done, but let me mention a couple of ways which we do this:
Intelligent and consistent use of category codes for objects. One of the code is specifically about retrofit and needs to be completed when the object is created. This is "retrofit needed" - sounds simple I know. But, if you create something bespoke - that never needs to be retrofitted - the best thing you can do it mark it like that. Therefore lots of time will be saved looking at this object in the future (again and again).
Replace modifications with configuration. UDO's have made this better and easier and continue to do so. If you are retrofitting and you think - hey - I could do this with a UDO - please do yourself a favour and configure a UDO and don't touch the code! Security is also an important concept for developers to understand completely. Because - guess what? You can use security to force people to enter something into the QBE line - you don't need to use code. (Application Query Security)

- Everyone needs to understand UDO's well. We all have a role in simplification.
 |
| If you don't know what EVERY one of these are - you need to know! |
OCM's can be used for force keyed queries. Wow!!! Did you know that you can create a specific OCM that forces people to only use keyed fields for QBE - awesome. So simple. I know that there is code out there that enforces this. This is like the above tip for security.


System enhancement knowledge. This is harder (takes time), but knowledge of how modules are enhanced over time is going to hopefully retire some custom code. Oracle do a great job of giving us the power to find this, you just need to know where to look:
Then product catalog (https://apex.oracle.com/pls/apex/f?p=103254)
Compare releases

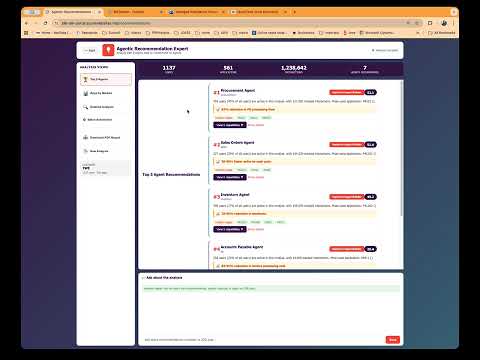
Calculate the financial impact. Once you know all of this, you can start to use a calculator like fusion5 have developed, this is going to assist you understand your technical debt and do research around it. We have developed a comprehensive suite of reports that allow you to slice and dice your modification data and understand what modifications are going to cost you money and which ones will not. Here are a couple of screen grabs. All we need to create your personalised and interactive dashboard is the results of a couple of SQL statements that we provide (or you run our agent - though ppl don't like running agents).

You can see that I have selected 5 system codes and I can see how much the worst case and best case estimates for the retrofit of those 5 system codes is. I can see how often the apps are used and therefore make an appropriate finance based decision on whether that should be kept or not. You are able to see the cost estimates by object type, system code and more. Everything can also be downloaded for excel analysis.